- Distributed Systems: Start small and add layers to your architecture.
- Sending the likes from the user to the server is trivial (HTTP Request), but delivering them from the server to other users is more challenging. This is done on a persistent connection, using HTTP Long Poll with Server Sent Events (using content-type text/event-stream)

- Next challenge: How can the real-time service handle multiple persistent connections? This is done using the Akka library. Each persistent connection has its own Akka Actor.
- How to distribute the Likes for a video stream only to the users that are watching it, and not all connections. The subscriptions (video:user table) are stored in memory. This is sufficient as the connections are local to the server, and if it dies, the connections are lost.
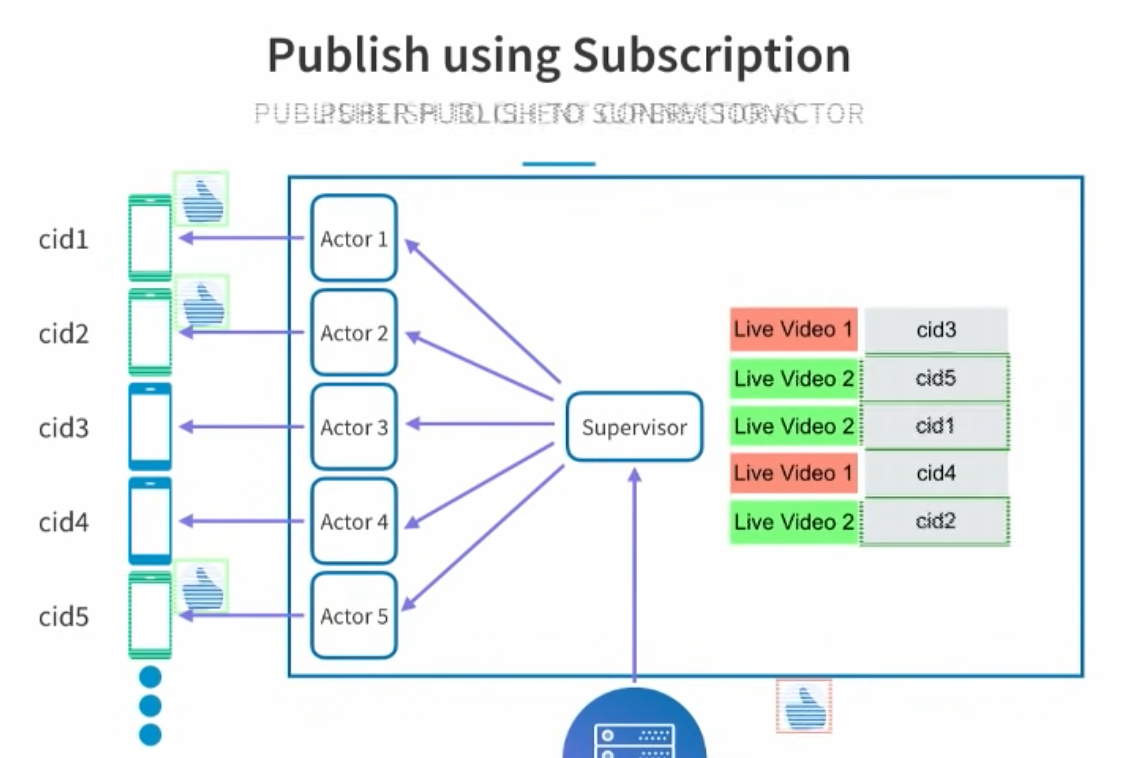
- To scale to more than one node, a real-time dispatcher is introduced. It receives the video:user mappings from the front nodes, and when a Like arrives, it forwards it to the specific front nodes, based on the mappings in this table.
- In order to scale to multiple dispatchers, the subscription table is moved to a key-value store (such as Redis) that is read and written to by the dispatchers. The frontend nodes still keep their own local subscription tables in memory.
- Next challenge: Adding more data centres. In-order to distribute likes to clients that are connected to other data centres, a dispatcher will forward the likes it receives to other datacentres’ dispatchers.
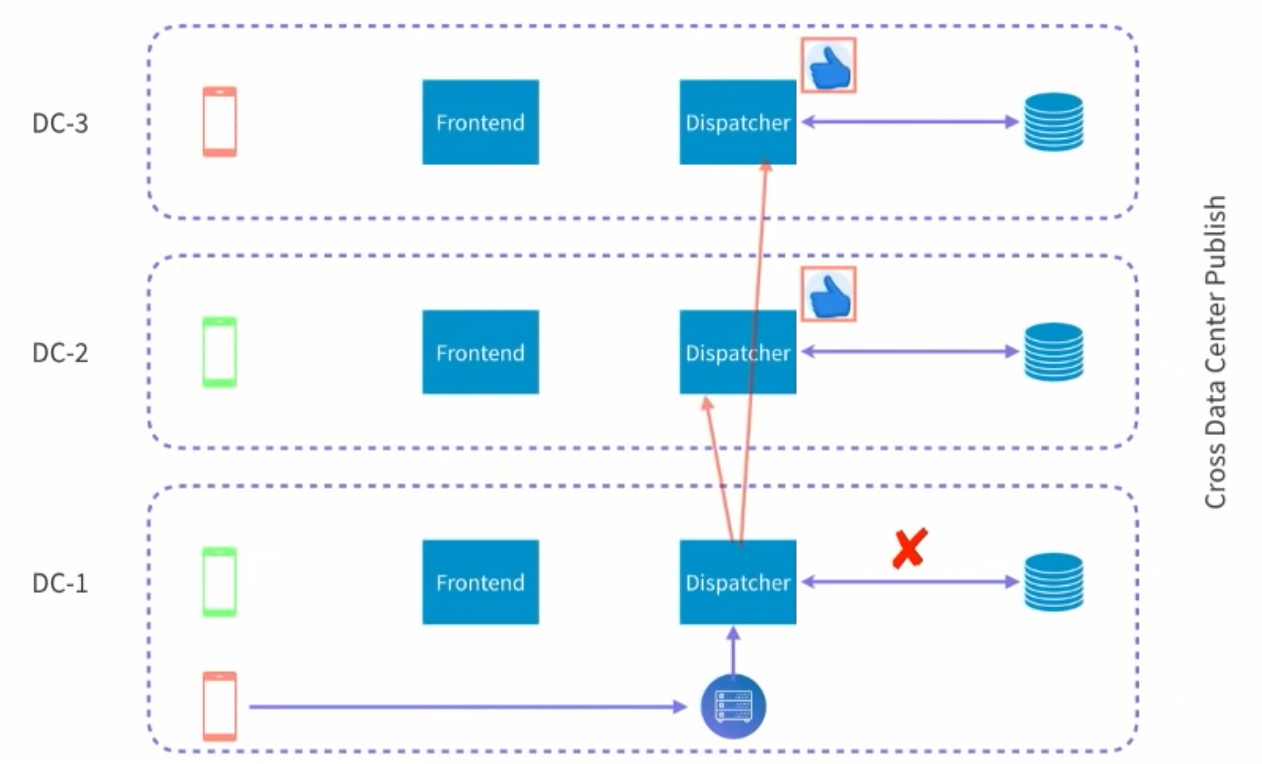
- Each machine can handle ~100k/connections (many problems such as file descriptor limits, memory exhaustion… needed to be solved), and each dispatcher handles about 5k/sec likes.
- Graph Databases: Schema-free objects (vertices) with directed relations (edges) between them. They make it easy to query edges in both directions, query a range of edges (2 to 5), search an infinite number of edges and find the shortest path between two vertices.
- They make queries with traversal easier (find friends of friends, users that share two hobbies with a user etc,.) but they are not optimized queries that are not based on relations (eg. find all users with age between 21 and 35).

- Every additional depth of search increases the complexity of searching.
- ArangoDB is multi-model DB (Key-Value, Document or Graph) with ACID support.
- There are multiple scaling challenges such as supernodes and big data.
- Supernodes are vertices with many inbound/outbound edges. Traversing them is expensive, and often only a subset of edges is needed (eg. latest 10 followers). Solutions include Vertex Centric Indices, to reduce the filtering of non-matching edges, but this is limited to one machine only.
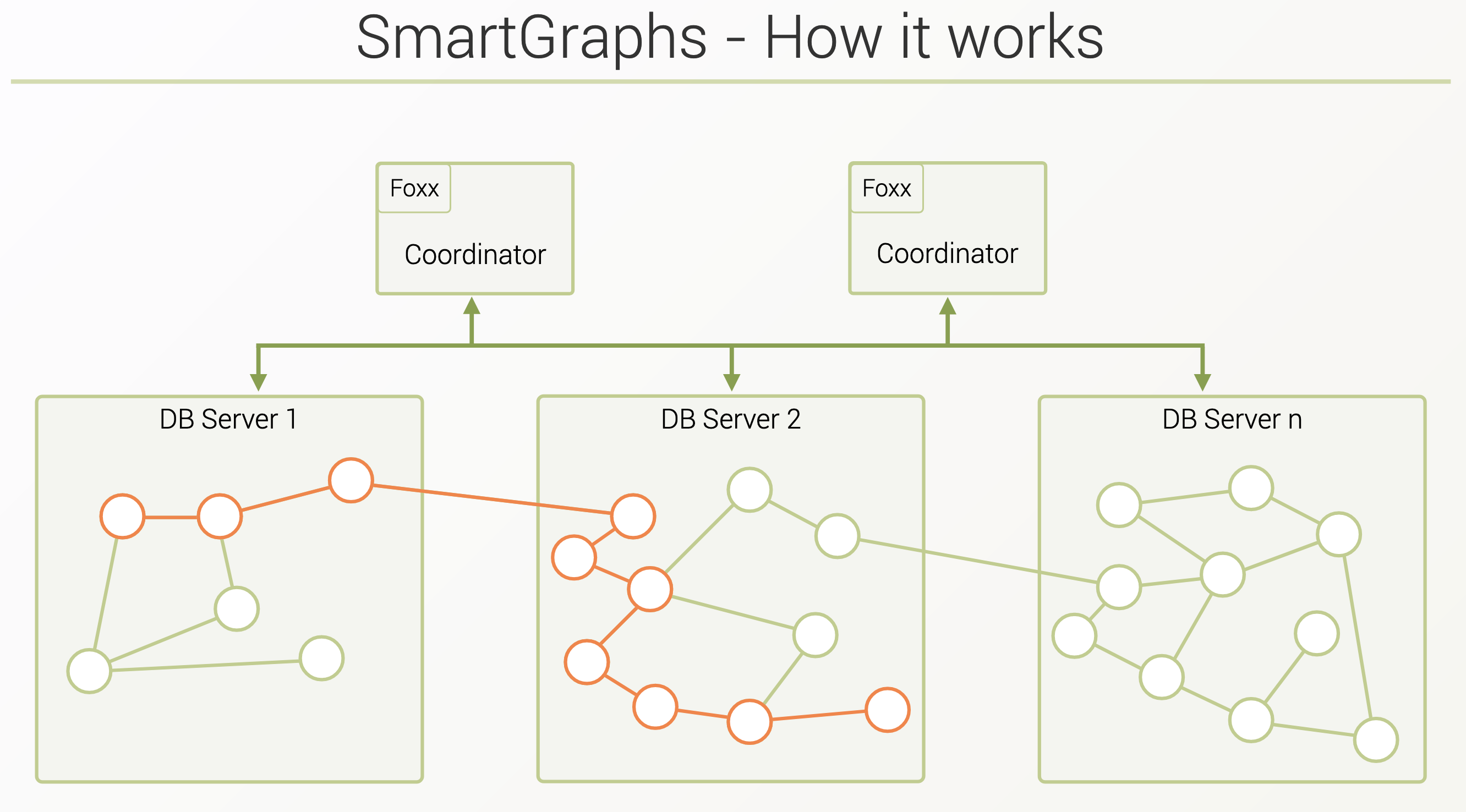
- Sharding means there’s no global view of the graph any more, and edges can be on different machines. As the network is the bottleneck in sharded environments, it’s important to reduce network hops. Queries are distributed, and results are merged locally.
- Random distribution is easy to implement and doesn’t require knowledge of the data. However, neighbors would likely end up on different machines, as well as edges and their vertices.
- Most other graph databases use Index-Free Adjacency: Every vertex has two lists of edges (In and Out) that are stored on the same machine.
- Domain-Based Distribution (ArangoDB Enterprise): Recognizes natural distribution of graphs (country, lists of friends, etc,.). Most local edges end up in the same group and the rare ones (cross-groups) end up on different nodes.
- Batch Processing: Leverage parallelism and computing power on all machines, while reducing network overhead. Pregel framework by Google is used to dispatch messages from a Master server to Workers on all servers, that read/write only one vertex (and its edges) at a time.
- Given Uber’s features and constantly changing business needs, it’s important to choose the right abstraction for geo-temporal data: A single-table OLAP.

- Many of Elasticsearch’s features support this use-case (built-in aggregate functions, sub-second response time, operable by a small team, idempotent insertions to deduplicate data, high-cardinality queries…)
- QPS can be a misleading metric, as some queries touch a few documents only. Doc scans per second is a better metric to measure scale.
- Scalability dimensions: Ingestion, Queries and Operations.
- It’s important to optimize for fast iteration, automation and simple operations due to the team’s small size. Thus, the team started small by getting things right for a single-node (disabling unused fields like _source and _all, and analyzed, tuning the JVM…) and set-up an end-to-end stress test framework in order to find the right configuration numbers.
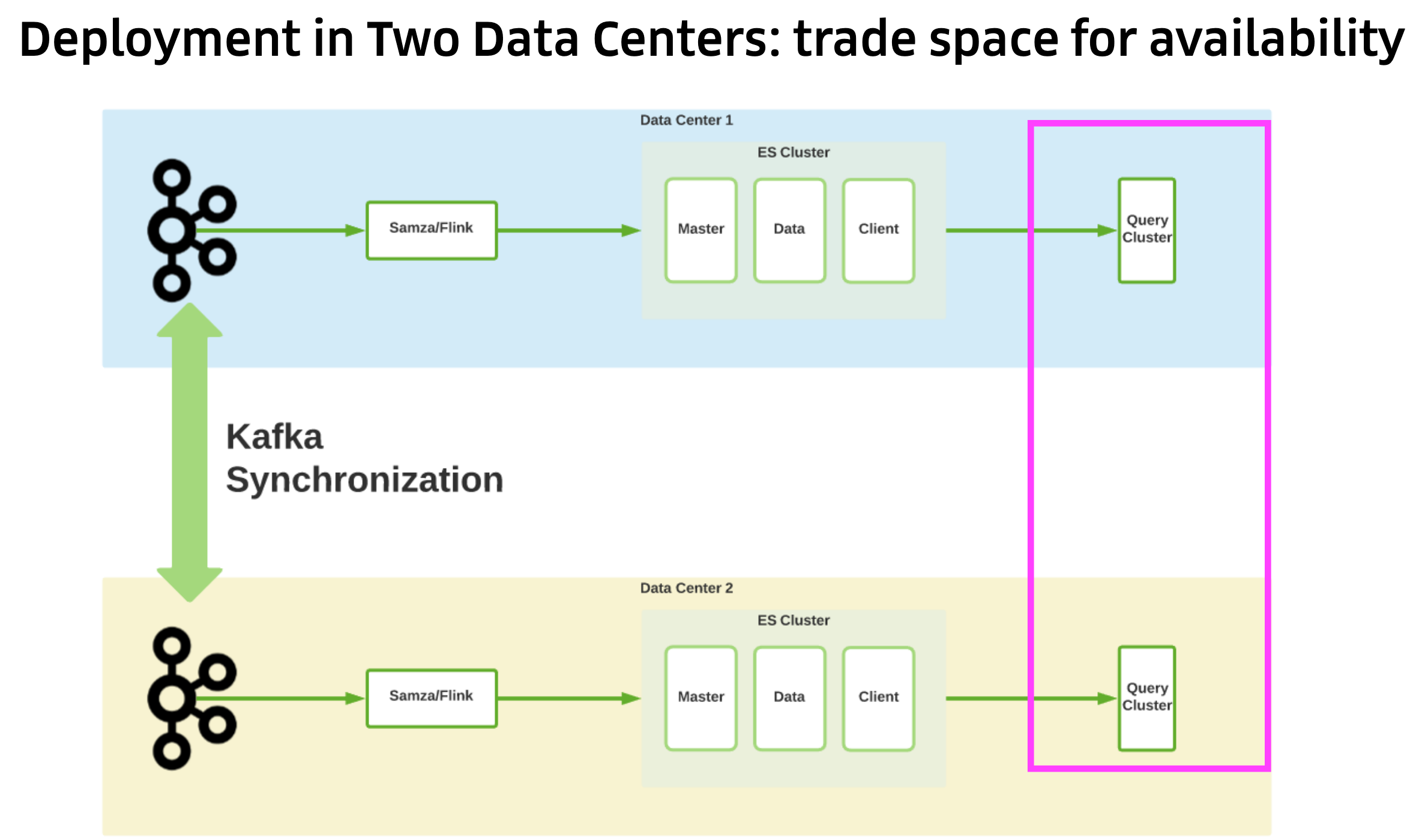
- Kafka was used to synchronize the data between the two data centres, making sure that ingestion still worked if a data centre went down, and that each data centre had all the data available to it. This was a trade-off between space and availability.
- When the volume of data is large, optimizations are needed. Humans do not need real-time too-granular data. By reducing redundant data (eg. drivers location pings in the same location), removing unused fields, and using bulk writes the event source data was reduced from 3TB/day to 42GB.
- A Query Layer was added to optimize ES queries, abstract the separate clusters, reject expensive queries, and save the users from learning ES query language.
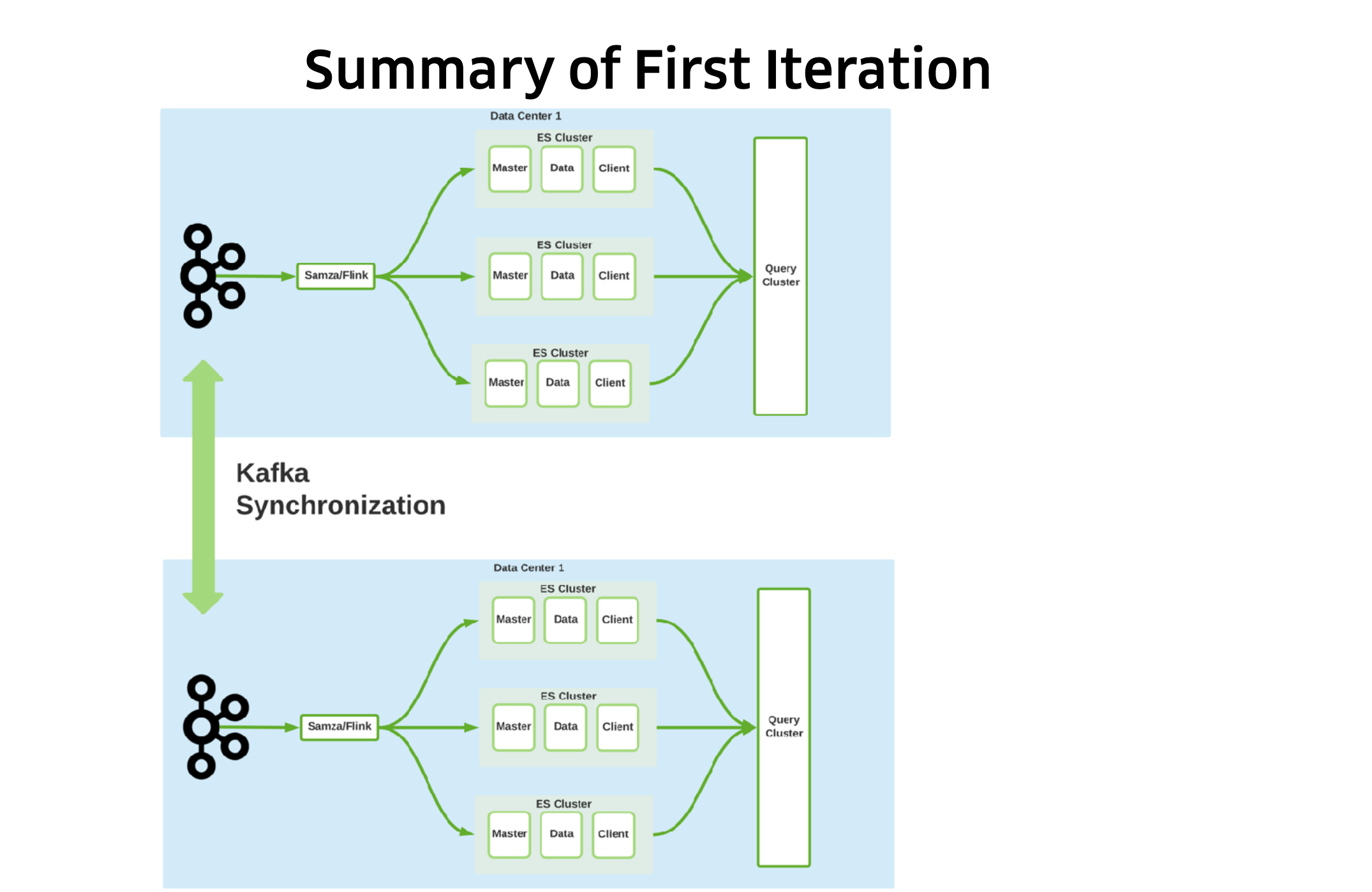
- There were a lot of failures leading to this successful first iteration, such as applications going haywire. This was solved by implementing distributed per-cluster and per-node ratelimiting.
- As the workload evolved, users started querying months of data. A read-aside Timeseries cache for the Query cluster was added. Redis was used as the cache store, and the key is generated based on normalized query content and time range. Multiple cached time-ranges can serve as building block to retrieve the response for a bigger time-range.
- Delayed execution can be achieved by providing cached but stale data for long-running queries.
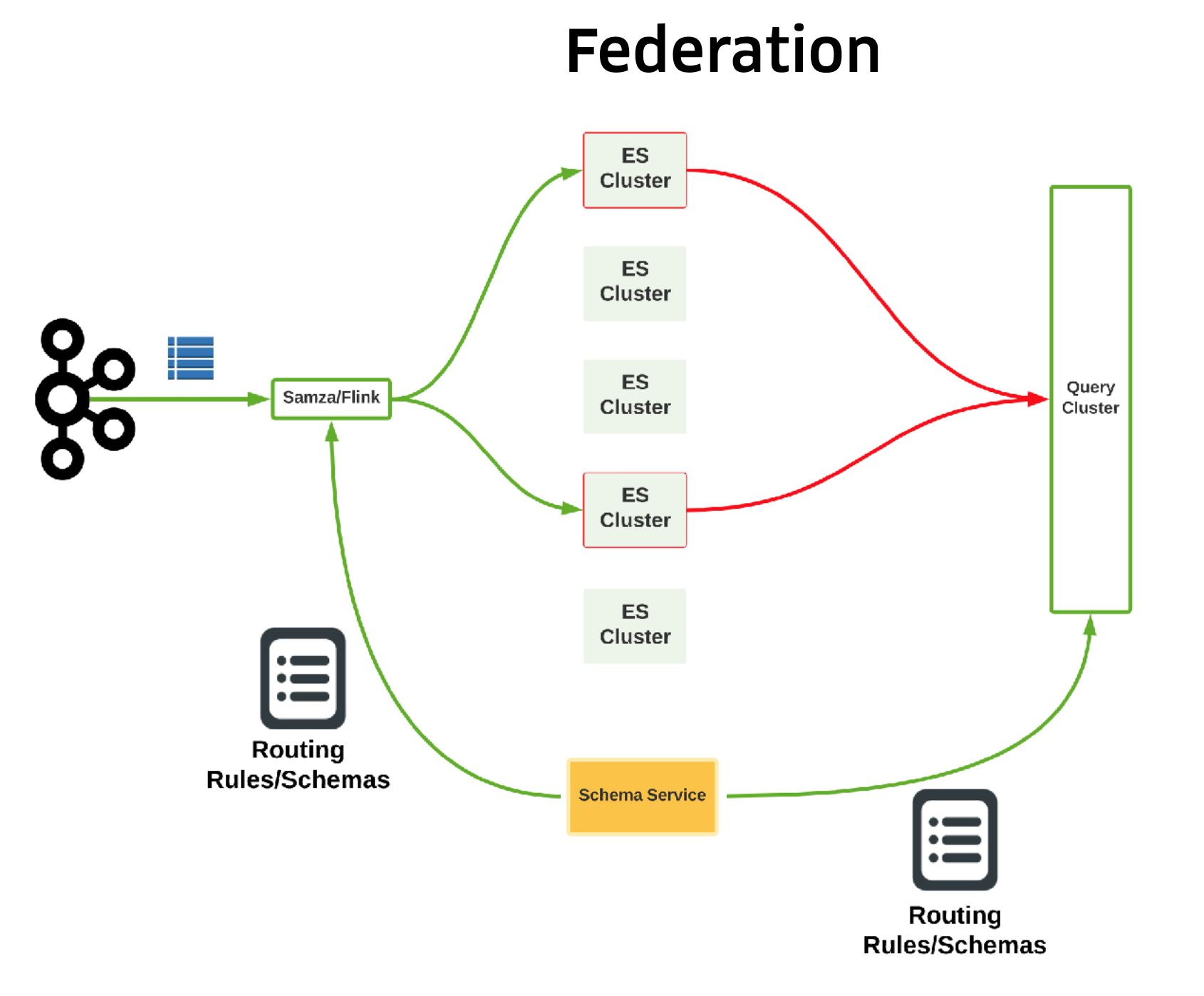
- As the clusters size increased, they became harder to operate. Federation was used to split clusters into smaller ones, and implement schema-based dynamic routing.