- On CodeSandbox, clicking “fork” creates an exact copy of the code’s environment in 2 seconds.
- In the past, the code was running fully in the browser, which was fast, but it limited what projects could run e.g. using Docker wasn’t possible.
- Instead of waiting ~5 seconds for a normal VM to boot, Firecracker can spawn a MicroVM in ~300ms. This is used to power serverless products like AWS Lambda.
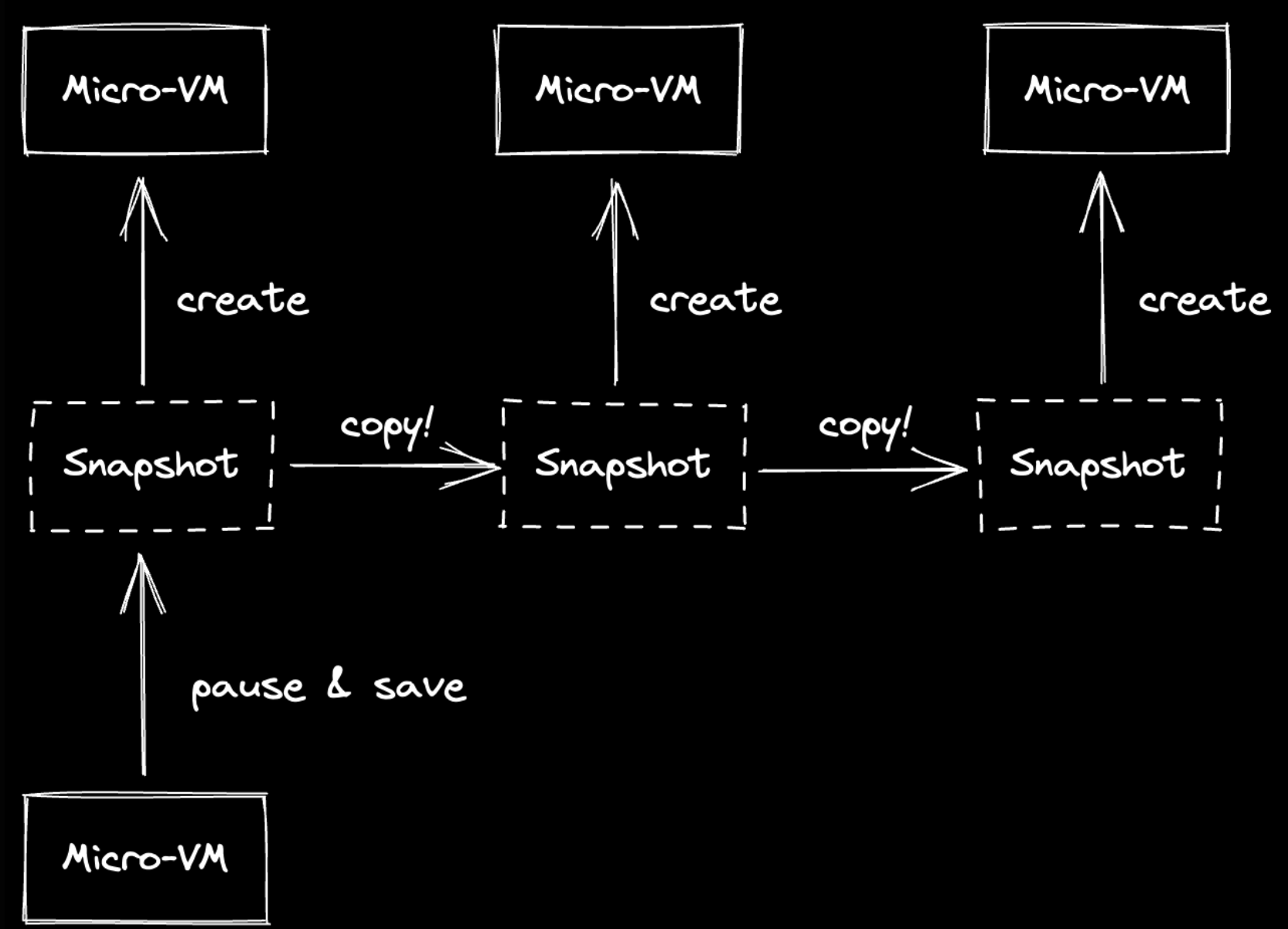
- However, cloning a repository and installing the dependencies can take up to 1 minute. Ideally, clicking “fork” on CodeSandbox should continue where the old VM left off.
- With Firecracker, it is possible to pause the VM and create a snapshot (Machine configuration, memory and CPU states, etc.) Resuming is also fast, at around 300ms.
- One thing to note is that creating a snapshot of a VM pauses it during the snapshot, which means that a user can cause pauses to another user’s working environment by clicking “fork”.
- Calling create_snapshot() in Firecracker takes around 1sec per gigabyte of RAM available to the VM due to the cost of copying the memory files.
- Firecracker uses mmap() to lazily load a VM from disk. This means that a VM resume would read 300-400mb of memory instead of 12GB. Changes are kept in memory and only synced back into disk when create_snapshot() is called, which leads to multiple 1-2GB writes.
- When mmap() is called with MAP_SHARED, the writes are lazily synced back to disk by the kernel, instead of the memory is read, which means that most of the snapshot saving I/O will be done in advance. This reduced the total operation time from 8-12s to 30-100ms.
- Cloning a VM (aka. “forking the code/project”) similarly leverages copy-on-write and mmap(MAP_SHARED). This is done both for disks and memory snapshots.
- The gaming industry has a lot of constraints (hard deadlines, soft real-time performance constraints at ~33ms, using custom allocators, no STL…)
- Main Data-Oriented Design Principle:
- All programs exist to transform data from one form to another.
- It’s important to understand the problem and the hardware, in order to solve the problem efficiently.
- Latency and throughput are only the same in sequential systems.
- DOD is a response to the main 3 lies in C++: Software (not hardware) is a platform. Code is designed around a model of the world. Code is more important than data.
- Hiding data is implicit in OOP (world modelling). But this confuses two problems: Maintenance (allow changes to the data) and understanding data (critical for solving the problem). This leads to monolithic, unrelated data structures and transformations.
- These lies lead to poor performance, concurrency, stability, testability…
- Solve for the most common case first. Example: Storing key:value dictionary in memory, when in most operations, only key searching is needed. This leads to loading values unnecessarily. If keys are loaded separately, they will be more likely to be in the L2 cache.
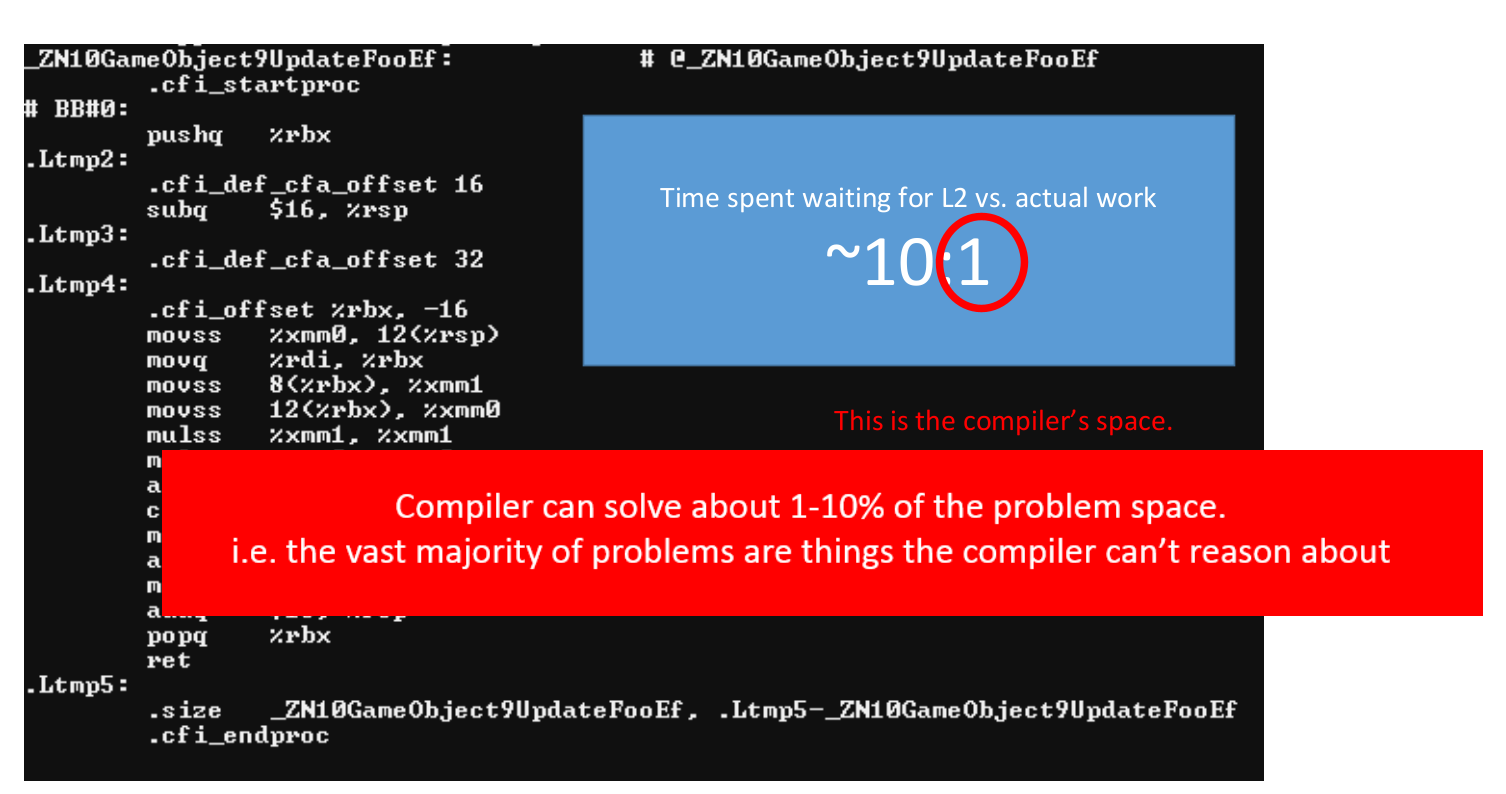
- Usually, programs spend 10:1 time ratio between waiting for L2 misses and doing actual work. The 1 is what the code/compiler can optimize (CPU instructions) while the 10 is what can be improved by focusing on the data.
- Eliminate ghost (unneeded) reads/writes and function calls. Move them out of loops.
- Improve density of information. Booleans that are read last-minute, and which have the same state very frequently, can be moved to a separate array that would improve cache usage.
- Better organized data improves maintenance, debugging and concurrency.
- Fastly is a proxy between the end-users and the origin servers. As there’s load balancing when sending traffic to the origins, health checks must be done from each datacenter.
- To reduce generated traffic, only one server should be responsible for health checks. As this data is shared between the servers, and there has to be one server responsible for this, this leads to different servers having different perspectives (on which origins are up/down).
- Systems like Consul and etcd can be used for atomic broadcasting. But this would be “too” strong consistency, which leads to the system stopping when there’s network partioning.
- We want availability instead, and specifically forward progress: It’s better to do two health checks, than zero.
- Determining ownership (with Rendezvous Hashing): Used to generate a priority list of servers, for each origin server.
- Failure detection: Using SWIM protocol, different servers check on each other. When there’s a check failure, the server asks other servers to double-check (e.g. #1 checks on #3, if failure, #1 asks #2 and #4 to check on #3). Hashicorp’s Memberlist can be used to manage cluster memberships and failure detection.
- Gossip: Used to communicate knowledge between members. A push-based approach means that knowledge is shared immediately (with a huge spike at the start) while a pull-based approach takes a while to share the knowledge (waiting for others to ask you), but doesn’t have the same spike at the start.
- Convergence: To guarantee causality, version vectors are used. The servers can send their versions of the CRDT (Conflict-free Replicated Data Type) maps of information. The receiving server compares this with their map of information, and respond with a delta map to be merged by the sending server. Eventually, all servers agree on the same state.
- Edge Computing: These are coordination-free distributed systems. One of the issues is that we are trying to provide “Single System Image” semantics, where the interface provided to the user appears as a single-system, while also maintaining causality. We need better distributed-systems designs.