- Understanding Data-Oriented Design helped Andrew Kelley (the creator of the Zig programming language) to move to the next level in terms of programming skills.
- lscpu command shows information about the CPU’s different caches. Reads from the next level (L1/L2/L3/RAM) are an order of magnitude slower. A kernel call (which could be caused by a heap allocation) is even slower.
- Each cache line is typically 64 bytes. Data size and natural alignment are not the same. A struct{u32,u64,u32} is 24 size, 8 alignment but a struct{u32,u32,u64} is 16 size, 8 alignment. Adding a Bool would add 8 bytes in size, instead of 1.
- There are multiple tricks for reducing memory footprint.
- Using u32 values as indexes instead of pointers. Watch out for type safety.
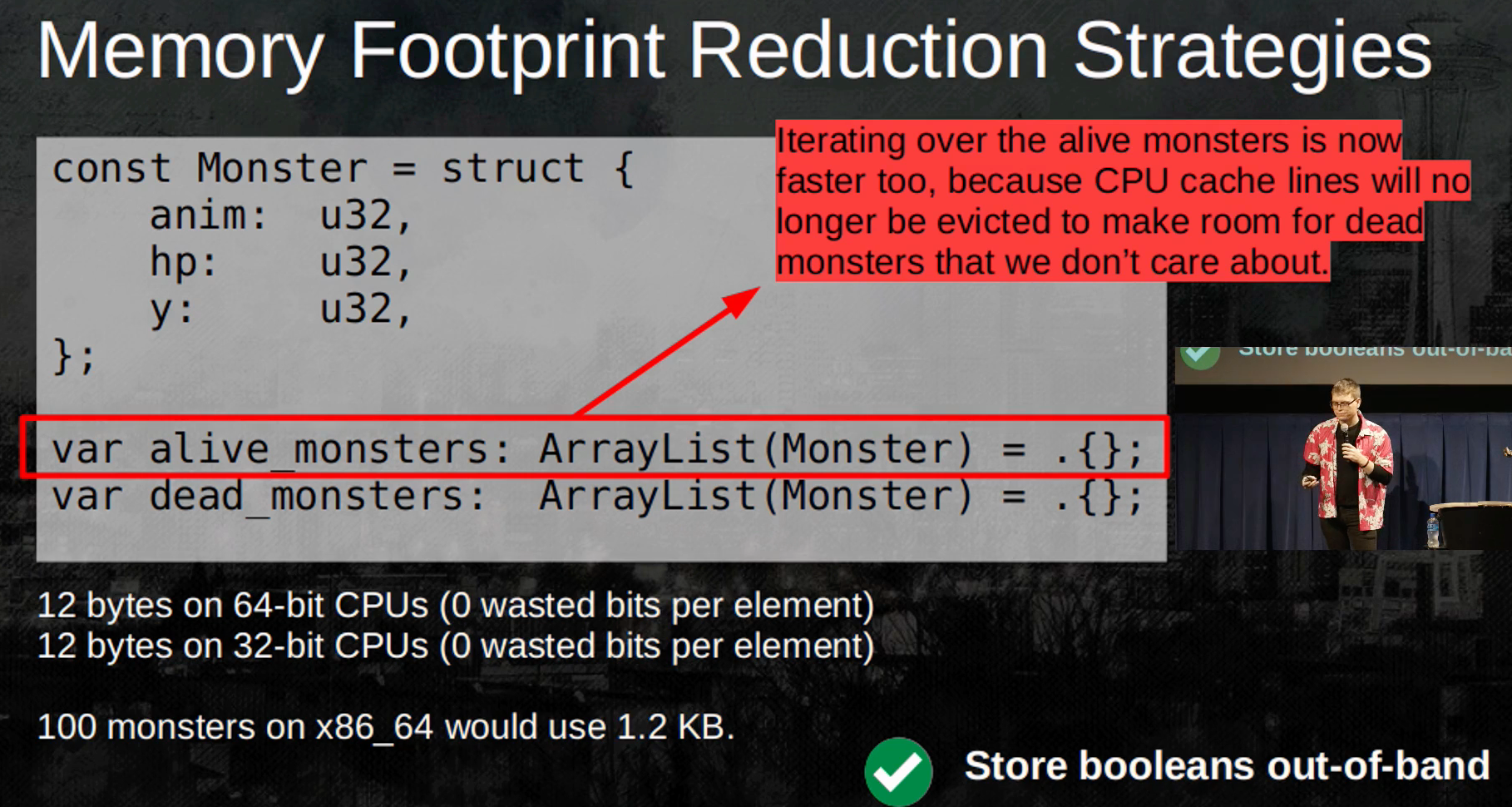
- Storing booleans out of band, by using a separate array to store the “dead monsters” instead of adding a Bool in the struct that specifies if the monster is alive (which would waste 7 additional bytes).
- Storing sparse data in hash maps: If an element in a struct is frequently unused (eg. boolean set to false in 90% of instances), we can track which structs actually use it in a HashMap (pointing to the indexes of structs that have it set to true).
- Many of these techniques were applied to the Zig Compiler at multiple stages: During tokenizing, the token struct size was reduced from 64 bytes to 5 bytes, AST nodes went from 120 bytes each to ~15.6 bytes on average…

- One of the main lessons of this talk is to keep the CPU cache in mind, identify what you’ve many things of in memory, and reduce the size of each of them.
- Many systems rely on randomness provided by the system for security (generating SSH keys, DNS Query ID, TCP sequence number, ASLR…)
- How are random bytes measured to be good ? Uniform distribution and unpredictability.
- The kernel relies on events that carry some entropy like mouse movements, keyboard clicks, and hardware events, but these are not uniform and usually not enough.
- CSPRNG (Cryptographically secure pseudo-random number generator) generates a random stream of bytes from these events.
- SHA-512 is an example of this. It takes a limited amount of input and generates a fixed amount of output, which would constitute the entropy pool.
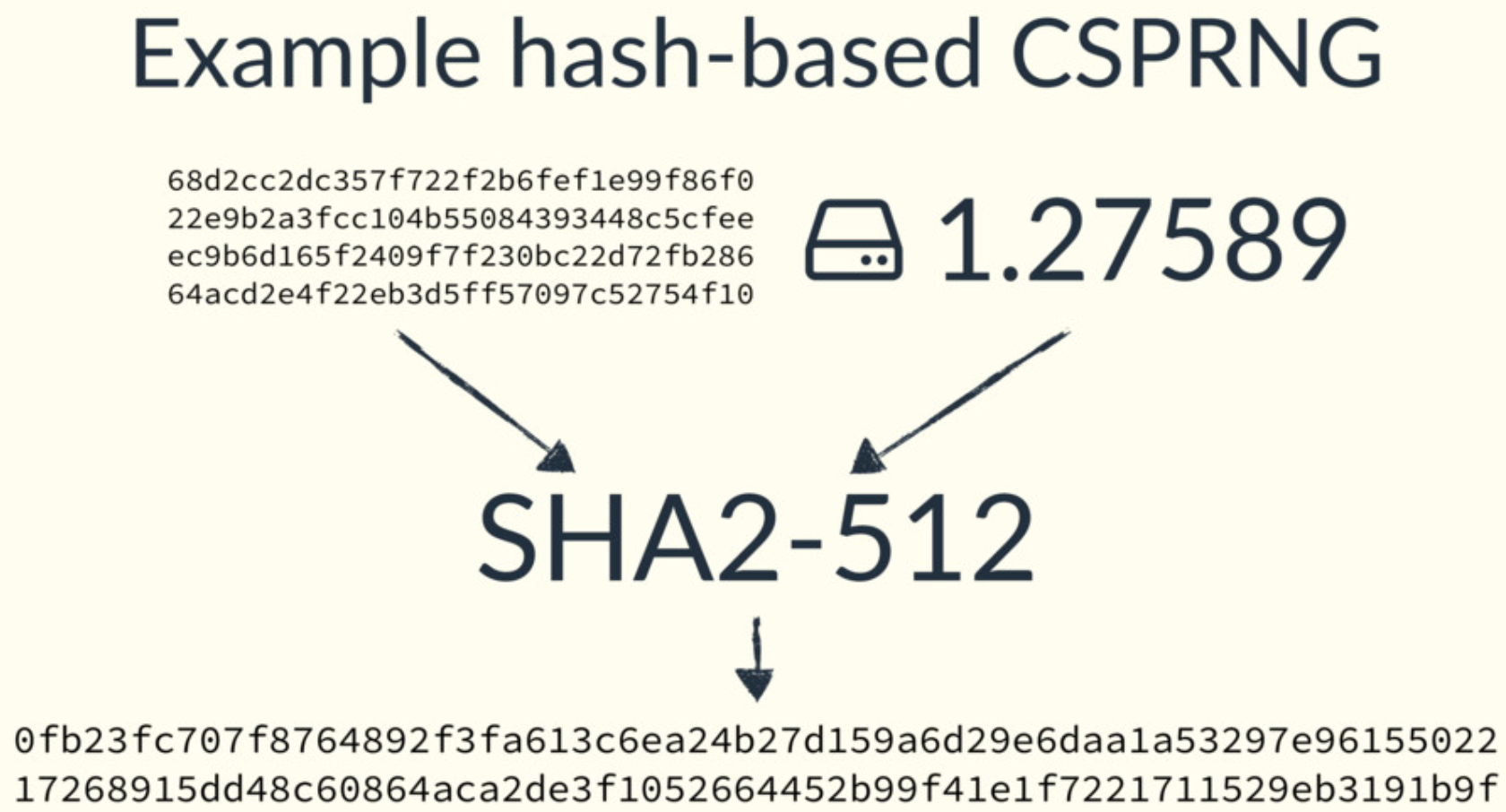
- This entropy pool can be concatenated with incremental IDs, to generate the random bytes needed by different applications. The result is uniform (as hash functions are uniform), unpredictable and unlimited.
- The Linux kernel CSPRNG is /dev/urandom. This is better than implementing it in userspace, as the kernel can observe these random sources like hardware events.
- Both /dev/random and /dev/urandom use the same pool of entropy. The output SHA is inserted back into the pool (instead of using an incrementing counter) to keep the output changing.
- /dev/random tries to guess how many bits of entropy were mixed into the pool and blocks if that number is low. This is however useless, as entropy doesn’t decrease or run out. Once unpredictable, is forever unpredictable.
- /dev/urandom is safe for crypto, and used a bit everywhere (BoringSSL, Python, Go, Ruby…)
- However, very early during the boot process, /dev/urandom could be predictable as it might not be seeded yet.

- Design Requirements for this caching system: Very heavy read load, geographically distributed data, externally handled persistence and a constantly evolving product.
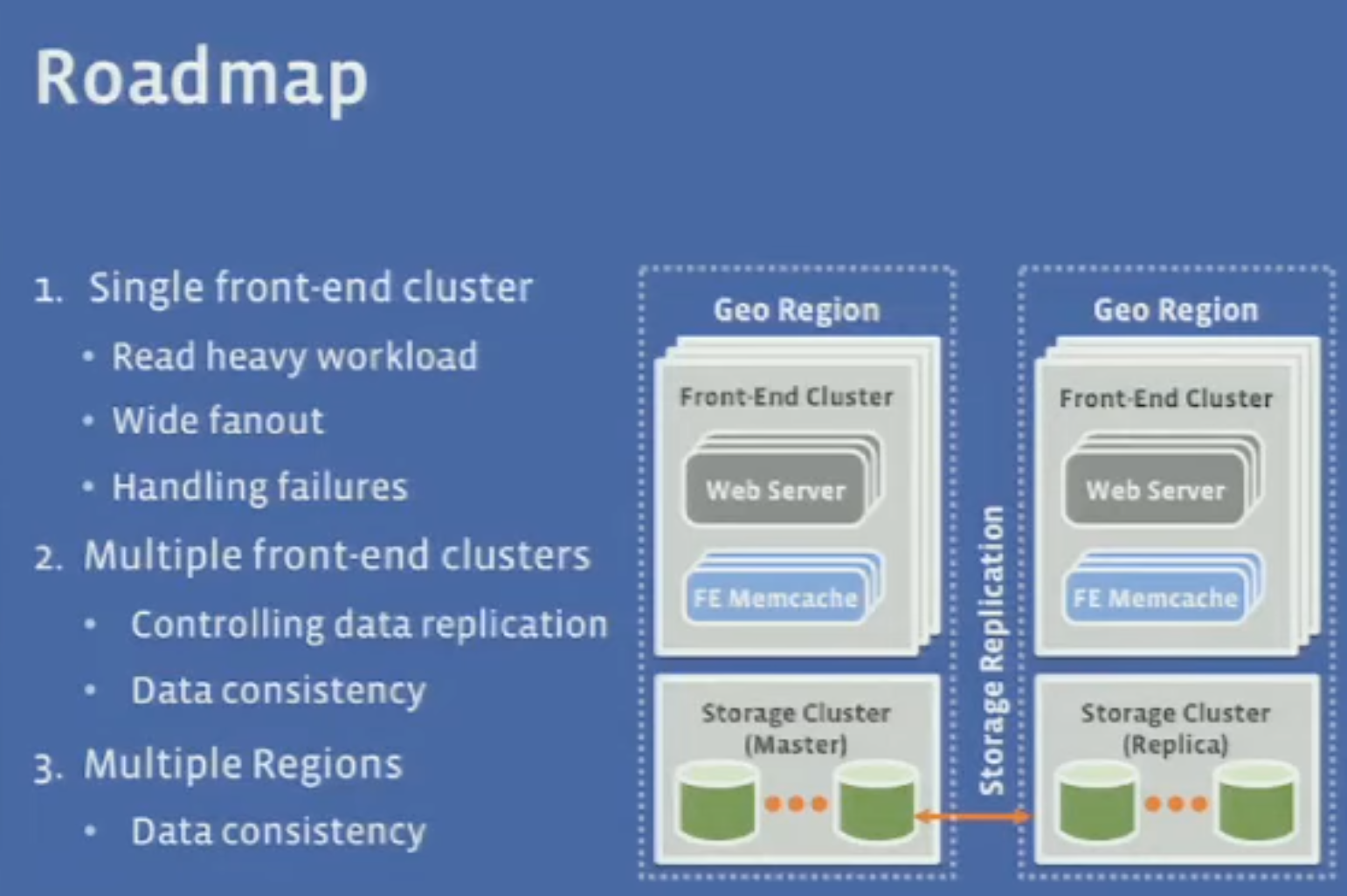
- Memcached is the basic building block for this caching system. With a single front-end cluster of instances, the challenges are handling heavy-read loads, wide fanout and handling failures.
- With multiple front-end clusters, data replication and consistency become challenging. For multiple regions, data consistency becomes even more challenging.
- A separate cache is needed due to the high-fanout of queries when data is sharded in multiple database nodes.
- With a look-aside cache, the key is read first from the cache, and a DB lookup is done on cache misses. On key updates, a DB write is executed, before issuing a delete to the cache. Deleting is idempotent, unlike direct updates of the cache. It also supports better the “demand filled” cache model.
- A problem with look-aside caching is stale sets, where two concurrent writes happen, the DB and the Cache may end up with inconsistent values as they are updated separately. Facebook extended the Memcached protocol by adding a lease-id on cache misses, that gets invalidated by the server on deletes. The set action is disallowed if the lease-id is invalid at the server.
- Another issue is the thundering herd problem on simultaneous cache misses, where all the web servers would end up accessing the DB at the same time. Facebook extended the protocol by offering the cache’s client the option to wait for the value to be fetched (as a cache miss was triggered recently) or use a slightly stale value.
- Consistent hashing is used to distribute data over multiple Memcached instances. Examples of problems include Incast Congestion where the client would query multiple keys from multiple cache instances, and the responses return at the same, overwhelming the client. A possible solution is to limit the max number of outstanding requests from the web server to the cache instances.
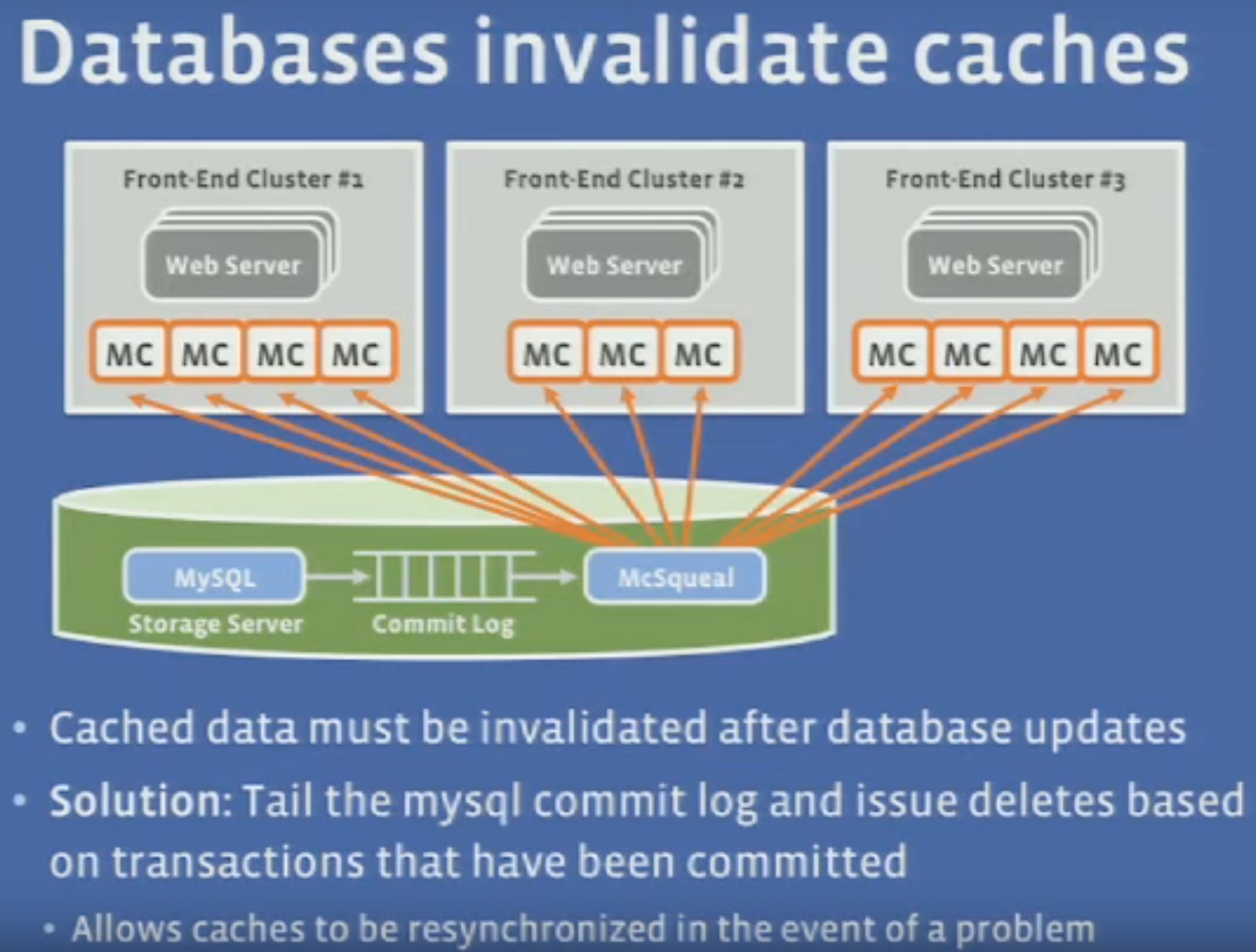
- With multiple clusters of caching, data consistency is a challenge. The solution for this is to make the databases invalidate the cache after updates, by using a commit log that issues cache deletes after transactions were committed.
- This invalidation pipeline generates too many packets, and as a solution, data is aggregated to Memcache routers which distribute the updates to other clusters’ Memcache routers, reducing inter-cluster bandwidth and simplifying the configuration.
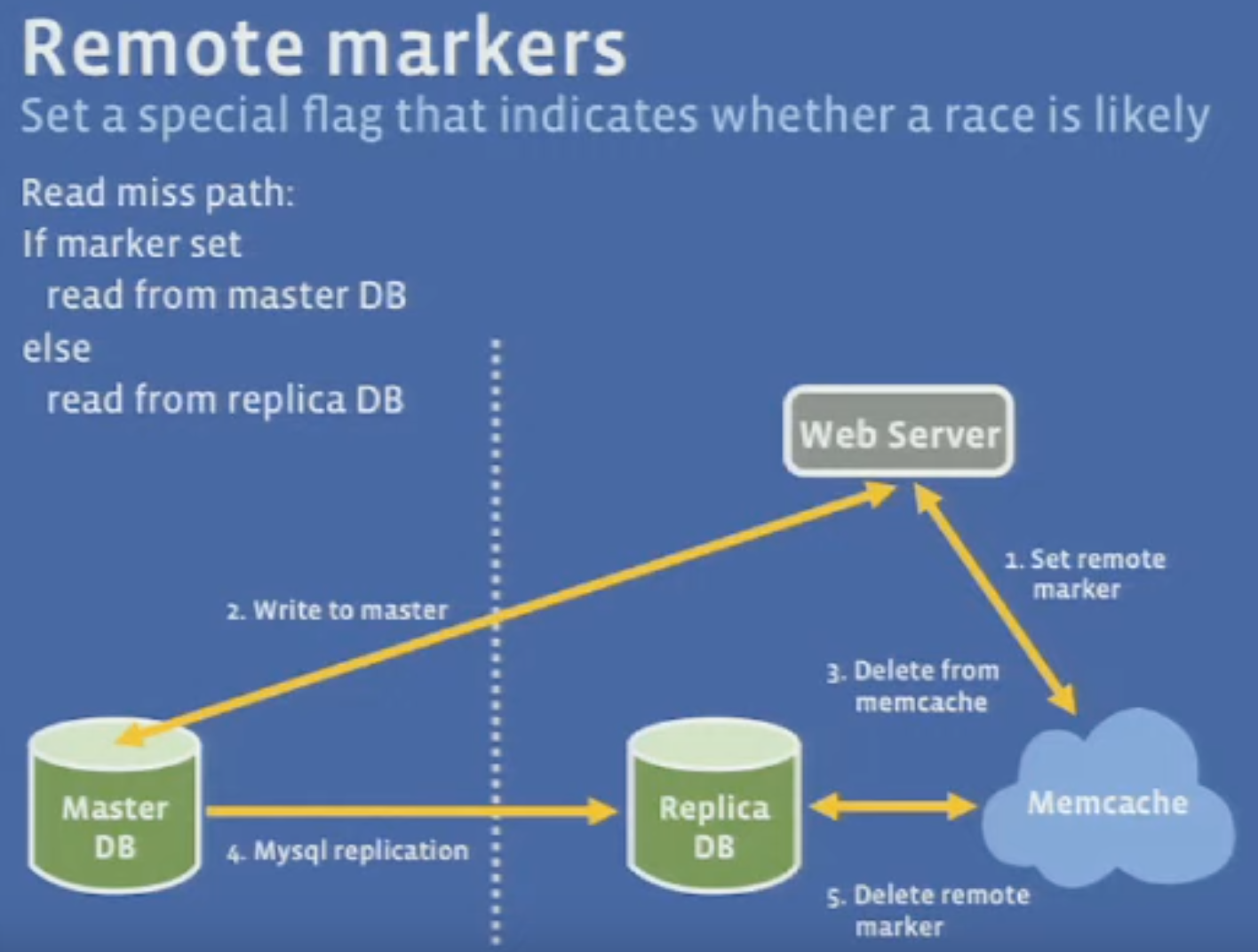
- In a geographically distributed setting, one region has a set of Master databases, while other regions contain replicas. Writes are cross-region to the Master DBs, before deleting from the local Memcache. Still, another local server may read from the Replica DB (before replication from Master DB occurs) and would update the local Memcache with a stale value. To solve this, a marker on the local Memcache is created before executing the cross-region write.
- Lessons learned: Push complexity to the client when possible, operational efficiency is as important as performance, and separate persistence from caching to scale them independently.