- Applications use system calls like open()/read()/write() to write data to the disk. The file system may however buffer modifications in the page cache in RAM, making those pages dirty.
- As those writes are periodically written to disk, they are vulnerable to being lost. For correctness, fsync() is used to flush those changes immediately. Another issue solved by fsync is the ordering of writes.
- Durability is hard, as fsync can fail. Either before writing to disk eg. insufficient space or while interacting with the disk eg. transient disk errors.
- It’s important to understand how both applications and file systems react to fsync failures.
- To understand file systems behavior, dm-loki is used to intercept all block requests that go to disk, and different workloads (single-block updates like SQLite/PostgreSQL or multi-block appends like write-ahead logs, Redis append-only…)

- File systems don’t handle fsync failures properly (marking dirty pages clean, not reverting in-memory data structures, failures not uniformly handled across different filesystems…)
- To test applications, a simple workload (insert/update) is used, and all key-value pairs are dumped after different fsync failures (application restart, page eviction, when running, machine restart…)
- CuttleFS (FUSE) is used to intercept file system requests from the application and inject different faults.

- Applications don’t handle fsync failures properly as well. Simple strategies are not good enough (eg. page cache can’t be trusted when recovering from WAL), and late error reporting like in Ext4 isn’t handled properly (double fsync helps here). Developers need to write file-system-specific code to handle failures properly as their behavior is not uniform.
- mvSQLite is a distributed SQLite-compatible implementation built on top of FoundationDB, that guarantees strong consistency and point-in-time (snapshot) reads.
- It is distributed, and not just replicated, in the sense that it offers scalable writing as well.
- In each transaction, multiple pages are read, and multiple (other) pages are written. Serializability comes from guaranteeing that none of the pages that were read in a transaction were changed before the writes happen.
- This is done by checking at commit time if the versions of the read-set have changed since they were read in the transaction.
- SQLite provides ACID guarantees, but mvSQLite goes beyond that with external consistency and synchronous replication. Asynchronous replication is supported, in order to provide global, eventually-consistent low-latency reads.
- SQLite, like most other databases, uses journaling to achieve atomic commits. Instead, mvSQLite uses the primitives provided by FoundationDB to achieve this.
- When pages are modified, only the delta is stored in order to overcome the overhead of storing every version.
- Sharding MySQL databases at Google was taking too much time, at some point in 2005, up to 2 years.
- The main needs: Horizontal scalability, no downtime, and ACID transactions with global consistency.

- In Spanner, Compute and Storage are separated. Each instance can contain multiple databases or splits, and each one of these splits is present on multiple instances. However, only one instance/compute is the leader (Paxos-elected) that accepts writes for that split.
- Splitting of the data happens on the range of keys, not by hashing the key.
- TrueTime quantifies the uncertainty of time or the worst possible drift between clocks in all data centers around the world.
- Consistent reads: Follower (for a split) will ask the leader if it’s okay to read. Either the leader tells the follower that it has updated data, or it tells it to wait for incoming data.
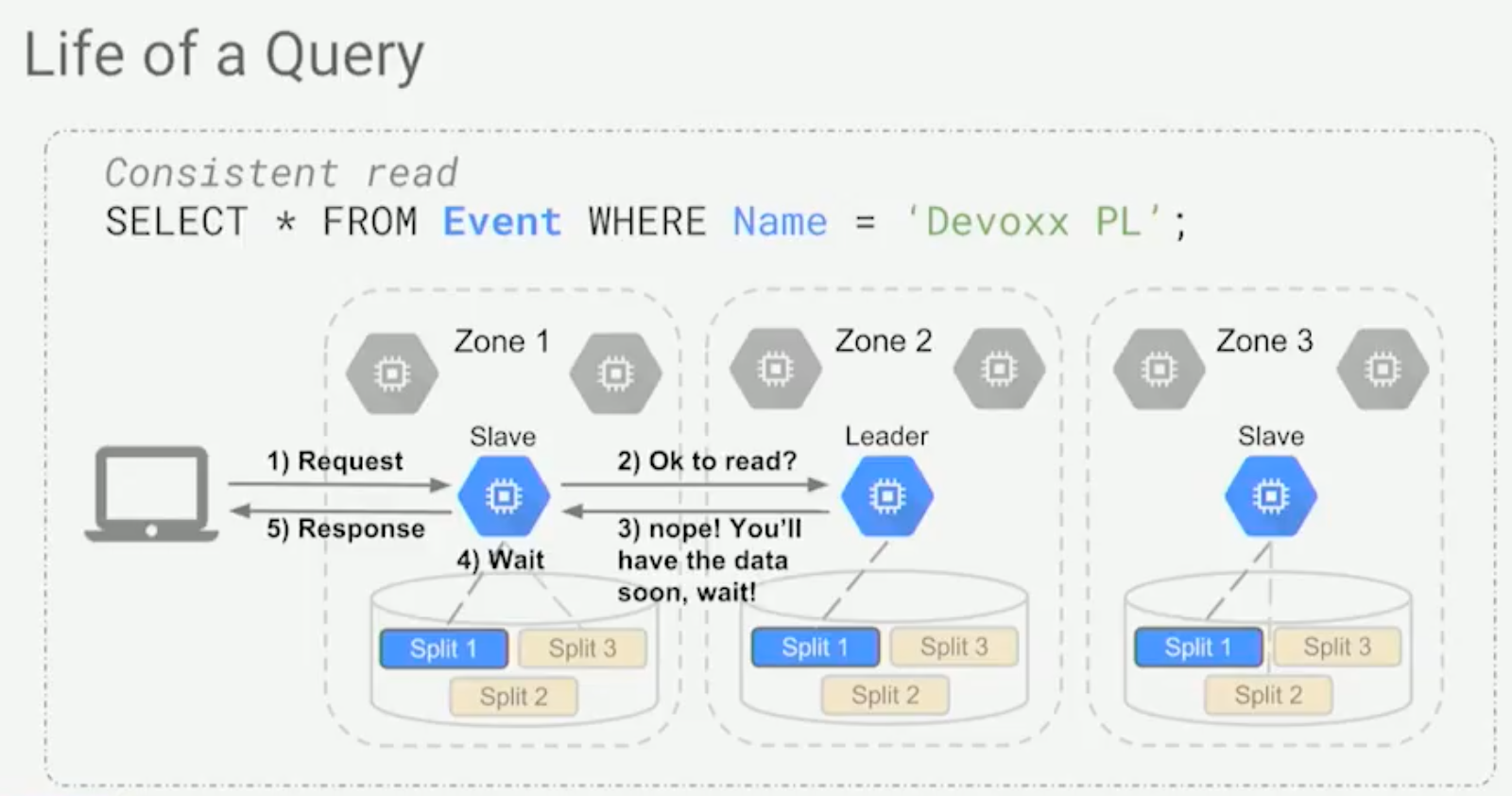
- It’s possible to do time-bounded (stale) reads, which means that the follower won’t have to always ask the leader.
- Interleaved data layout is used to scale horizontally. There are a few important caveats to avoid hotspots for writes such as not using monotonically increasing Primary Keys, as all the writes would end up in the last split. Use UUIDs instead.
- CAP Theorem: Pick two only AP (Riak and Cassandra) or CP (Redis, Memcached, Hbase, MongoDB…).
- Spanner is a CP system, but it’s also very unlikely to be unavailable, due to the multi-truth system. For that to happen, the majority of a Paxos group has to be down.