- Zalando migrated from a single monolith to +1000 microservices supported by +200 development teams. The Checkout service specifically has a lot of challenges due to many dependencies and points of failure.
- It’s important to retry when transient errors like network failures or service overloads happen. Make sure to use exponential backoff to not contribute to service overloading and make the situation worse.
- Circuit-breaker pattern: If the error rate is > 50%, fail immediately instead of retrying.
- Fallbacks (eg. standard delivery page on checkout) can be used as an alternative to error pages.
- Scaling is done both horizontally and vertically. However, more instances mean higher DB connection saturation, and that leads to Cassandra using more CPU. Fine-tuning Cassandra’s configuration is important here.
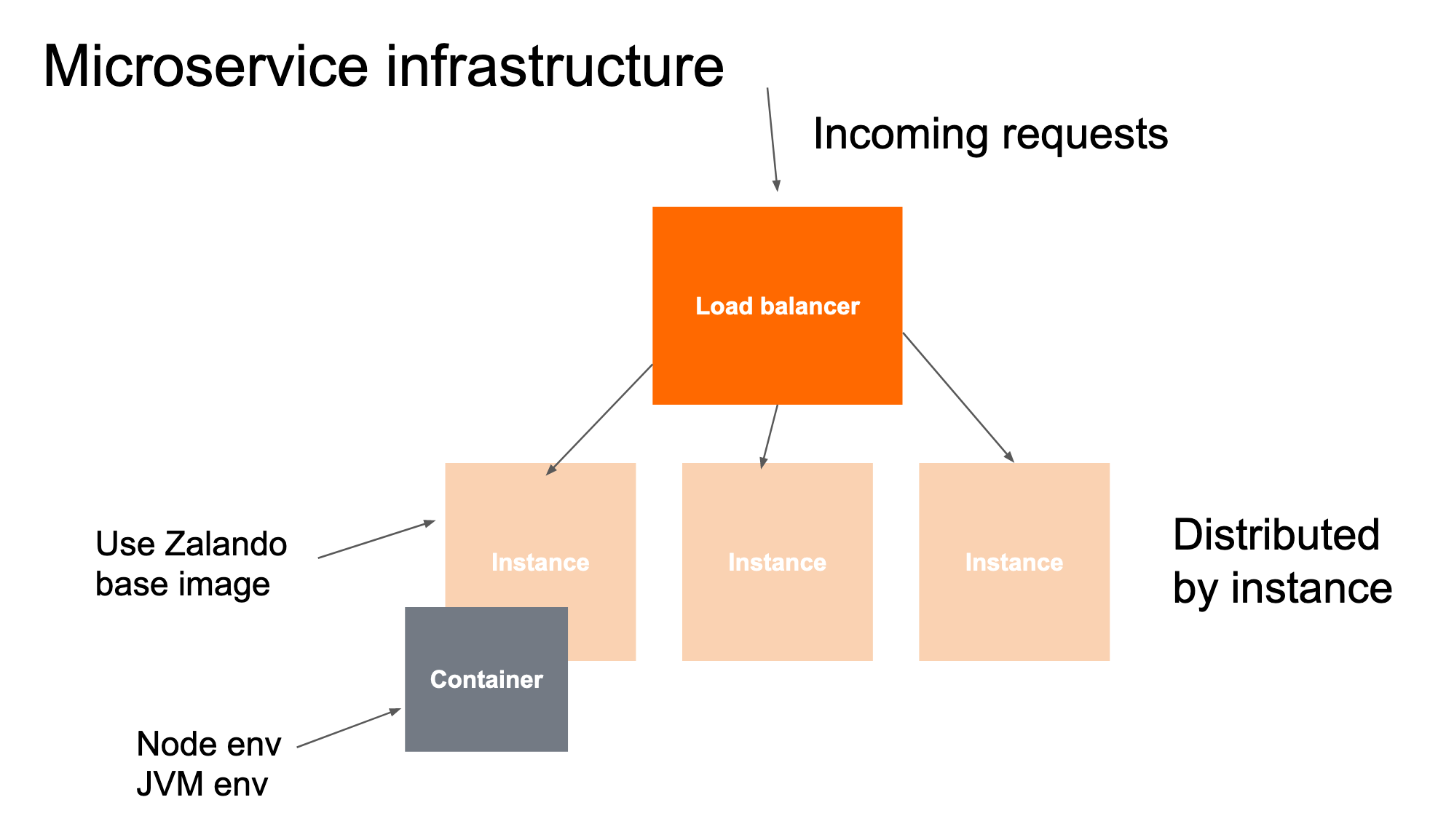
- Microservices can’t scale if the downstream microservices can’t scale accordingly.
- Monitoring: Both infrastructure layer and Microservice metrics.
- Infrastructure layer: Hardware (CPU Usage, Network traffic…), Communication (4xx/5xx errors, Healthy Instances count, Elastic Load Balancing connection errors), and Application platform (NodeJS metrics like event loop delay, heap summary…)
- Microservice metrics: API endpoints rate, response…
- Using dashboards to detect outages. Use actionable alerts instead (eg. no orders in the last X minutes, % of unhealthy instances, 4xx errors above a threshold…)
- Every incident should be followed with a postmortem with actionable items.
- To prepare for Black Friday, there’s a checklist for every microservice: Are points of failures known, are reliability patterns implemented, is there a scaling strategy, is monitoring in place, are the alerts actionable, etc,.
- Scalability in the context of the Edge is about taking more traffic, without service degradation. The focus here is on architecture decisions, rather than policies like retaining data for a shorter time.
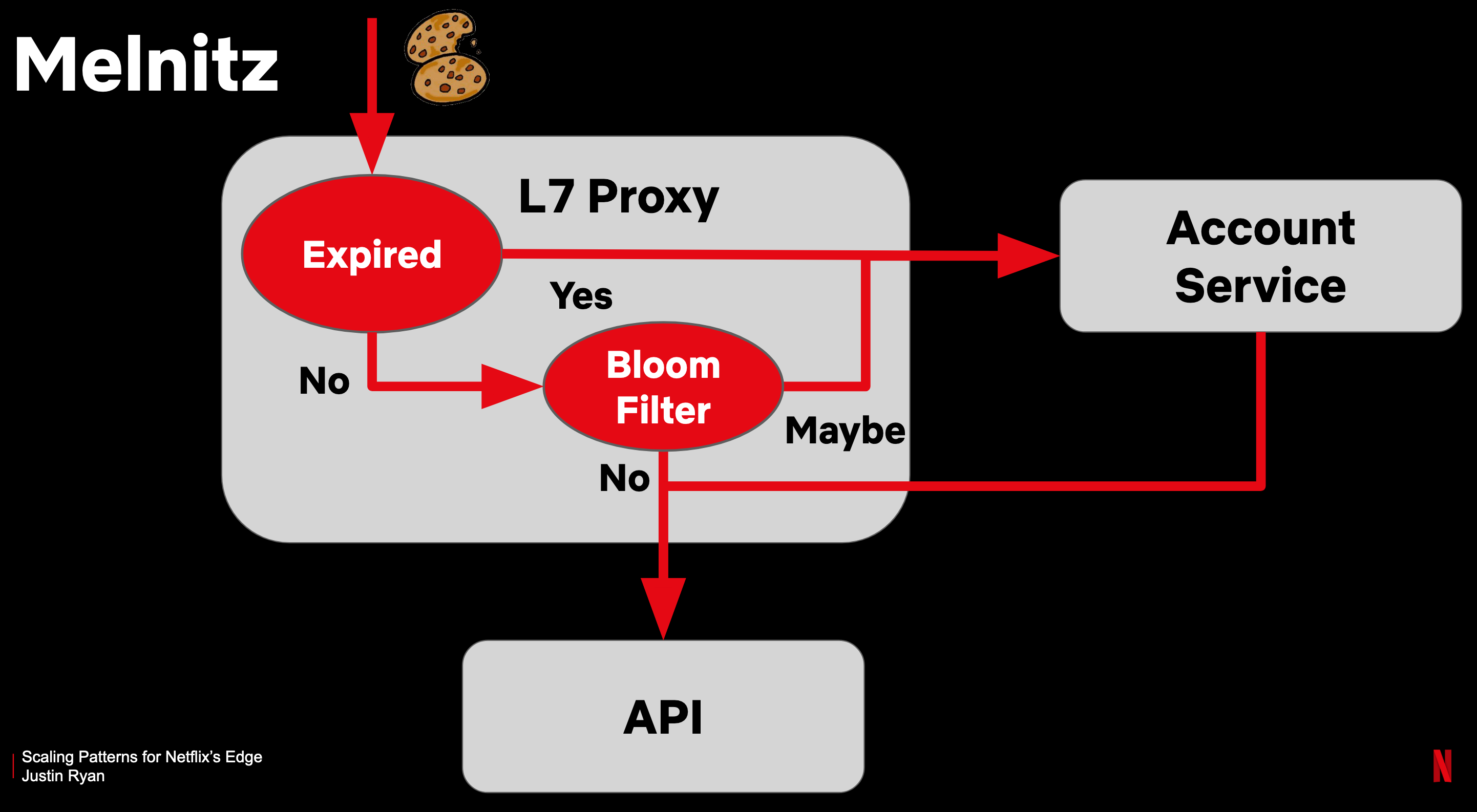
- Cookies are used to check if a user is logged in or not. The cookie contains information about its expiration time. The L7 Proxy forwards the request if the cookie is still valid, otherwise, it checks the account service, and generates a new cookie otherwise.
- However, the L7 Proxy still needs to check if a customer made changes to their account, which would invalidate the old cookie. To optimize this check, and reduce DB hits, a set of customer IDs that changed their accounts within the last 8 hours can be shipped to the L7 proxies. To reduce the amount of data sent to those proxies, bloom filters are used.
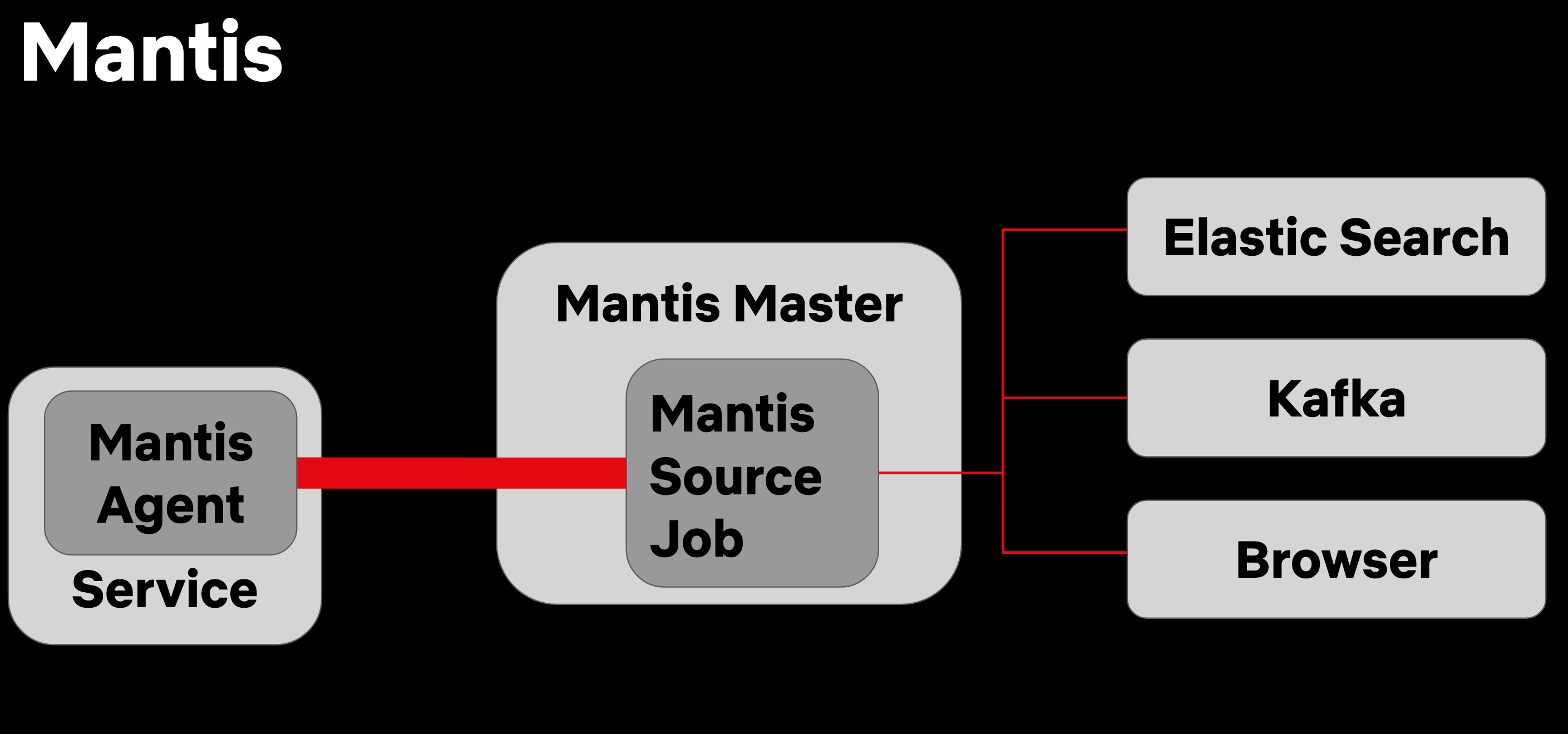
- The classic approach of searching through logs stored in Elasticsearch doesn’t scale. Instead of running queries on the logs store, Netflix’s Mantis allows sending the queries to its agents on those remote services and aggregating the returned results.
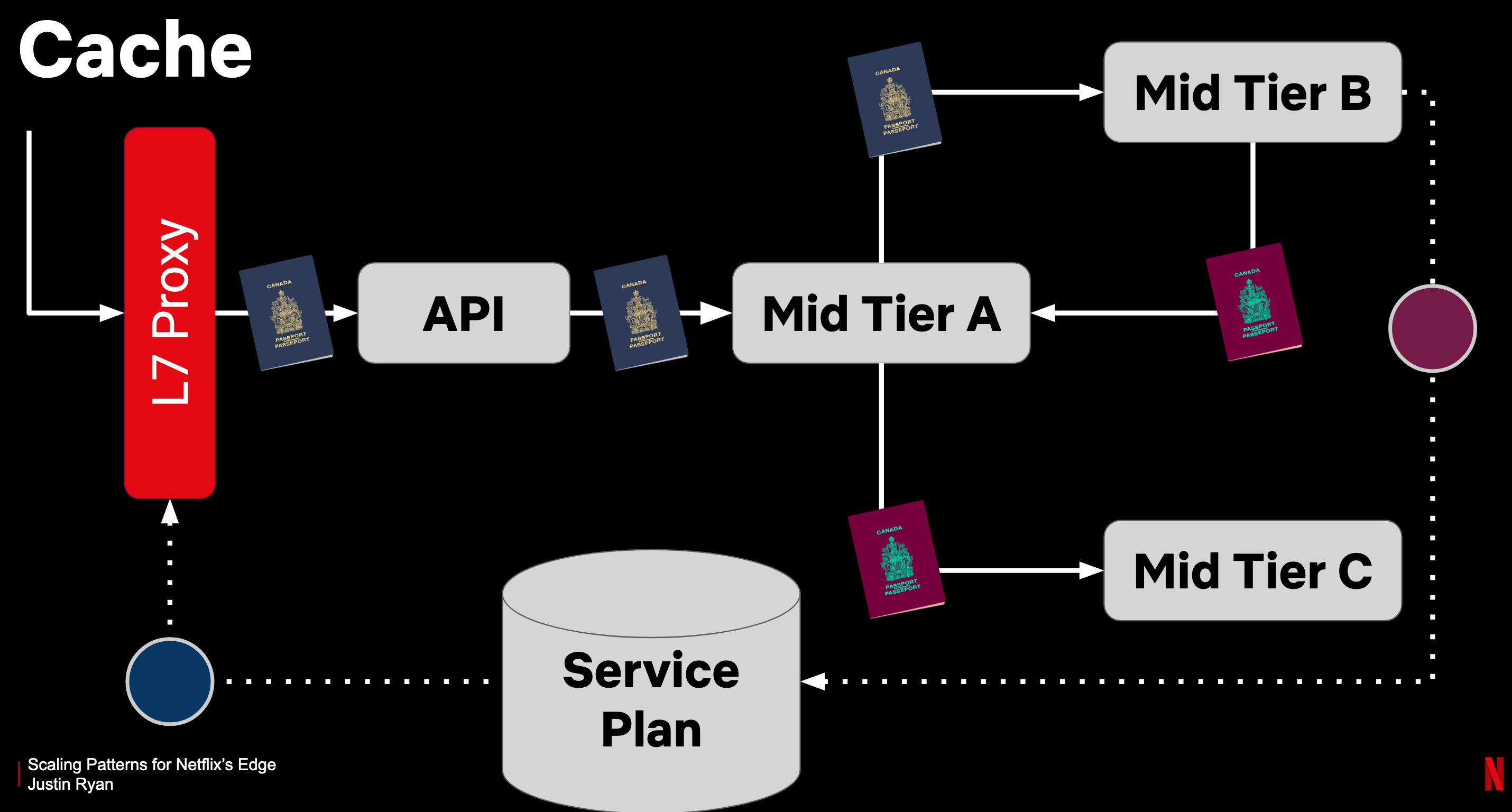
- Netflix’s Passport: is used for data that is commonly requested by different services (eg. user preferences, membership-level…). This increases the amount of traffic flowing internally but makes the DB requests consistent.
- Instead of each service querying the data from the DB separately, this is done by the L7 Proxy at the start of the request and forwarded to all downstream services with the request.
- If a service changes the data, they are responsible for forwarding the “new passport”.
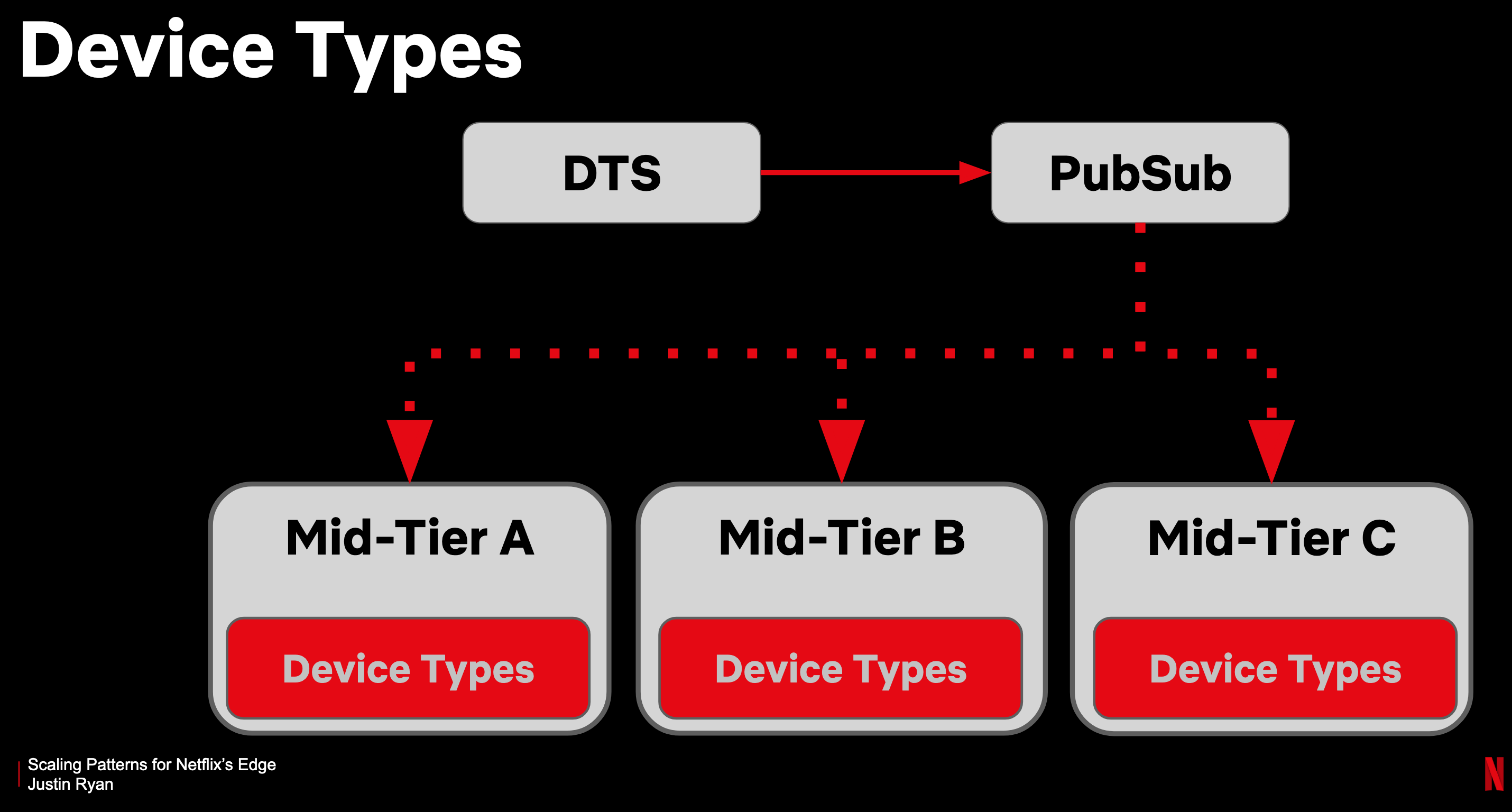
- Device Types: This used to be an internal service that was queried by many Mid Tier services in order to map IDs into device types. This had a lot of operational costs and was first moved into a PubSub architecture that the Mid Tier services would subscribe to, to get updates to the +100MB XML file that it distributes.
- Given that there’s a delay between when a device type is registered (eg. Netflix app certified for a new TV device) and when it starts being used, having stale/old data is fine.
- Therefore, the data was compressed into the client library’s jar, which ensured availability even when the PubSub service is down.
- Runtime refactoring: Refactoring the MSL (Message Security Layer) logic out of the API services, led to a 30% decrease in CPU usage and latency. This was largely caused by simpler code that led to shorter pause time and CPU usage by the JVM’s GC. The operational overhead of a separate service was worth it.
- In 2012, Dropbox’s storage was split between MySQL meta servers in Dropbox’s datacentres, and block servers in AWS S3. Most of the services were written in Python.
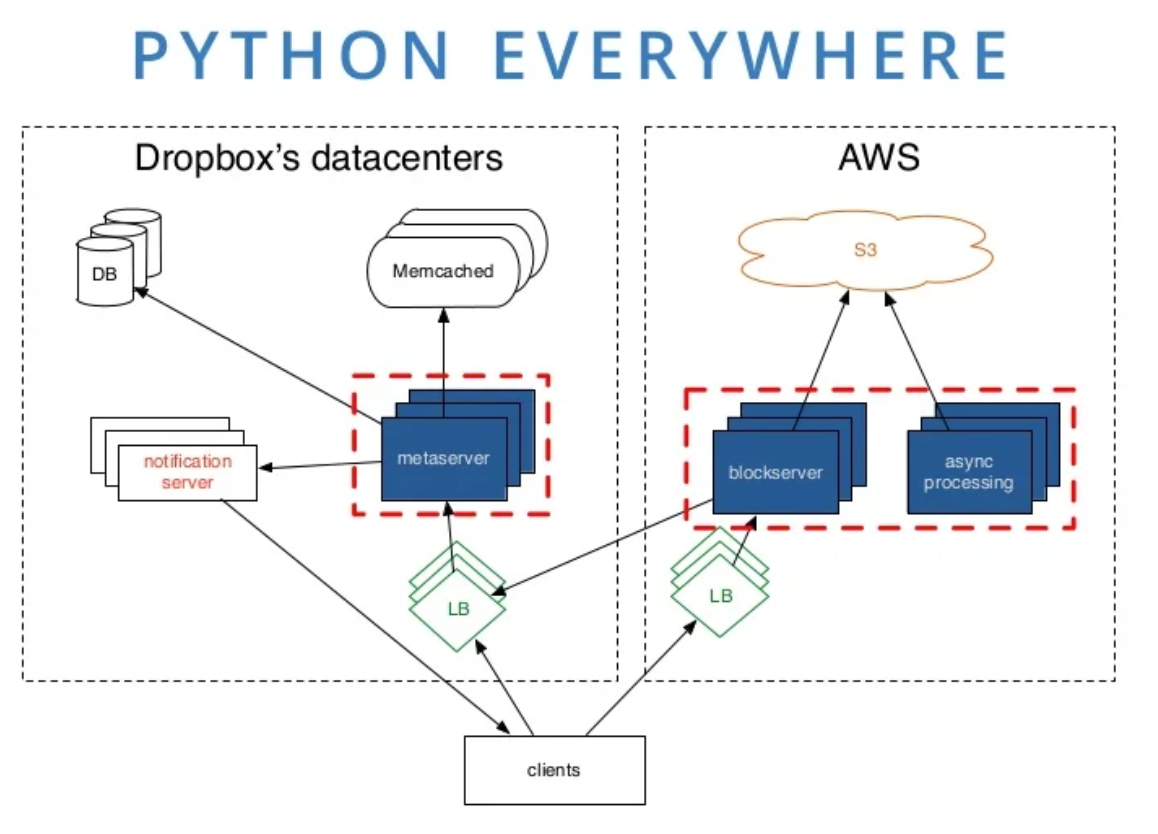
- Different clients (desktop, web, mobile…) used different metadata clusters, to improve resource isolation.
- Most internet companies have more reads than writes, and Memcache would help with scaling that. For Dropbox, reads/writes were at equal ratios. It meant that they had to early-on start sharding the DB to scale horizontally.
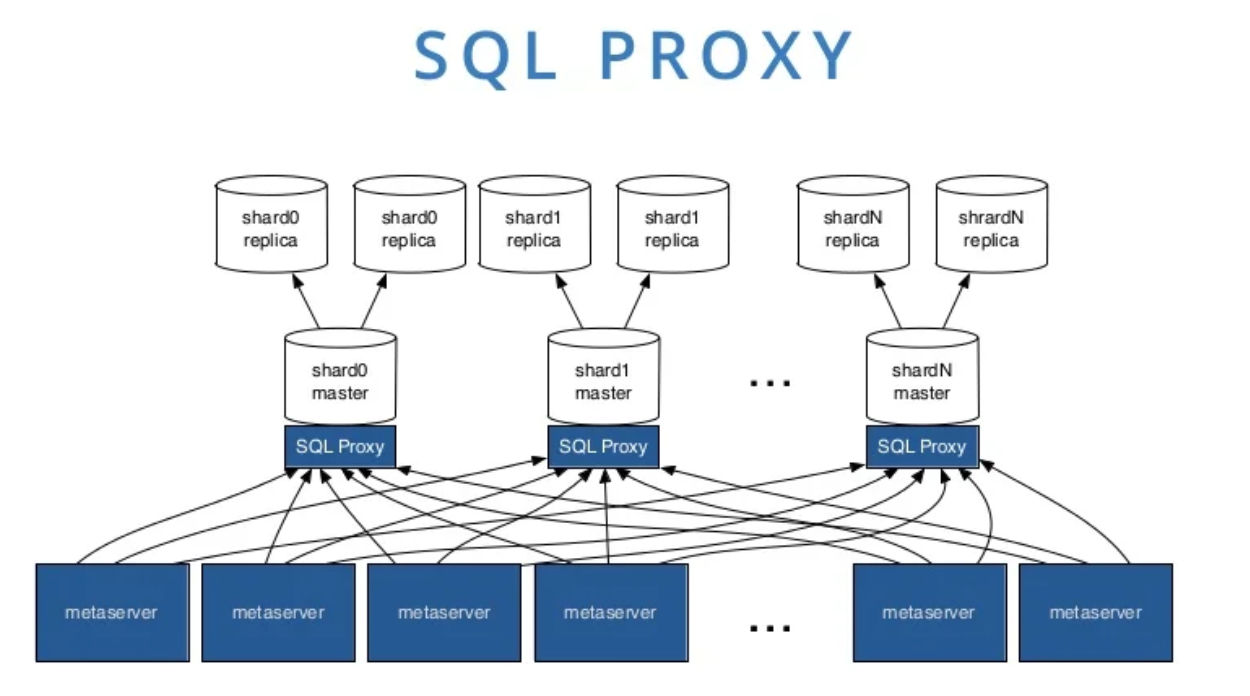
- At the time, MySQL 5.1 was used, and it scaled horribly with the large number of idle connections created by the separate Python processes. SQL proxies were added in front of the MySQL instances to alleviate the number of received connections.
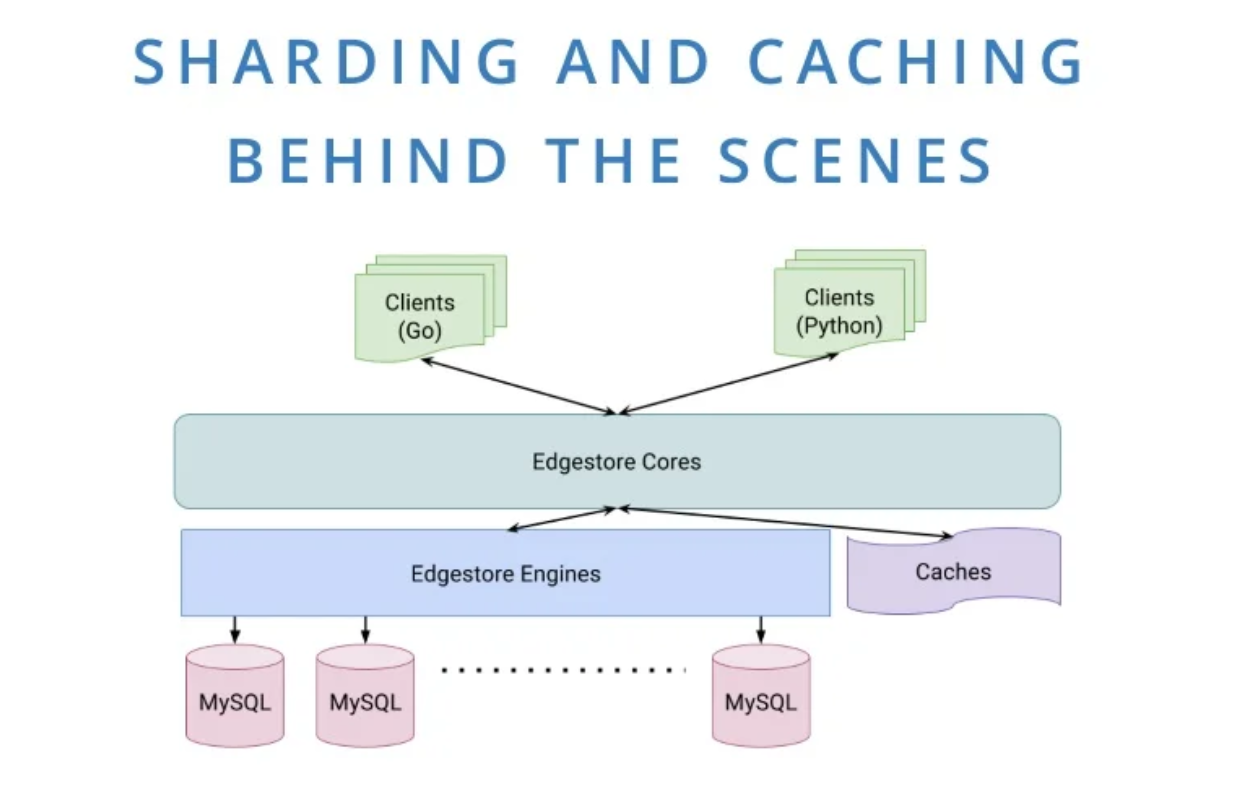
- As the organization grew in the number of employees, it became harder to figure out which changes or features caused performance issues for the DB. Edgestore was introduced as a metadata store that abstracts the lower details such as sharding and caching.
- When a DB shard is unavailable, a disproportionate amount of requests starts to fail due to request fanout. Using colocation (shard) IDs helps both with transactionality and performance, by using fewer shards per request.
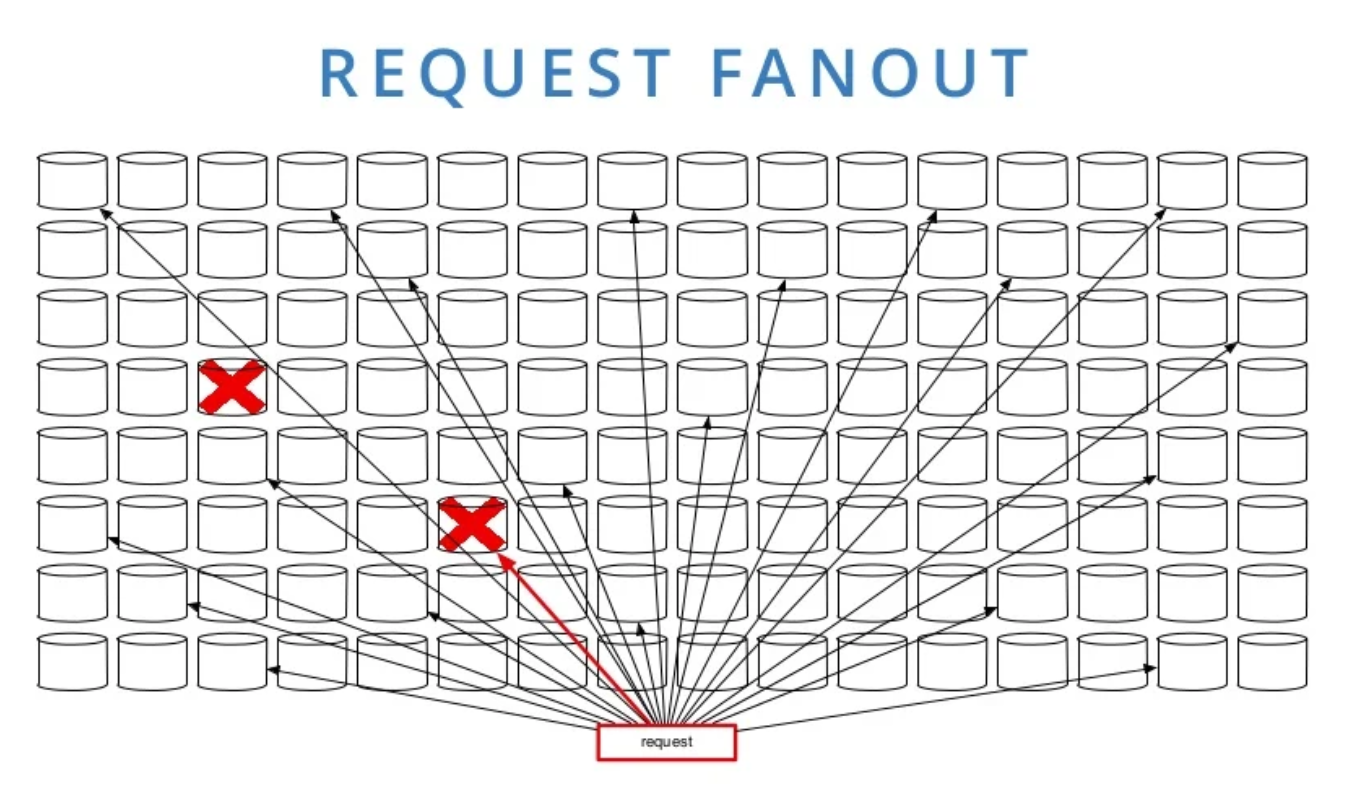
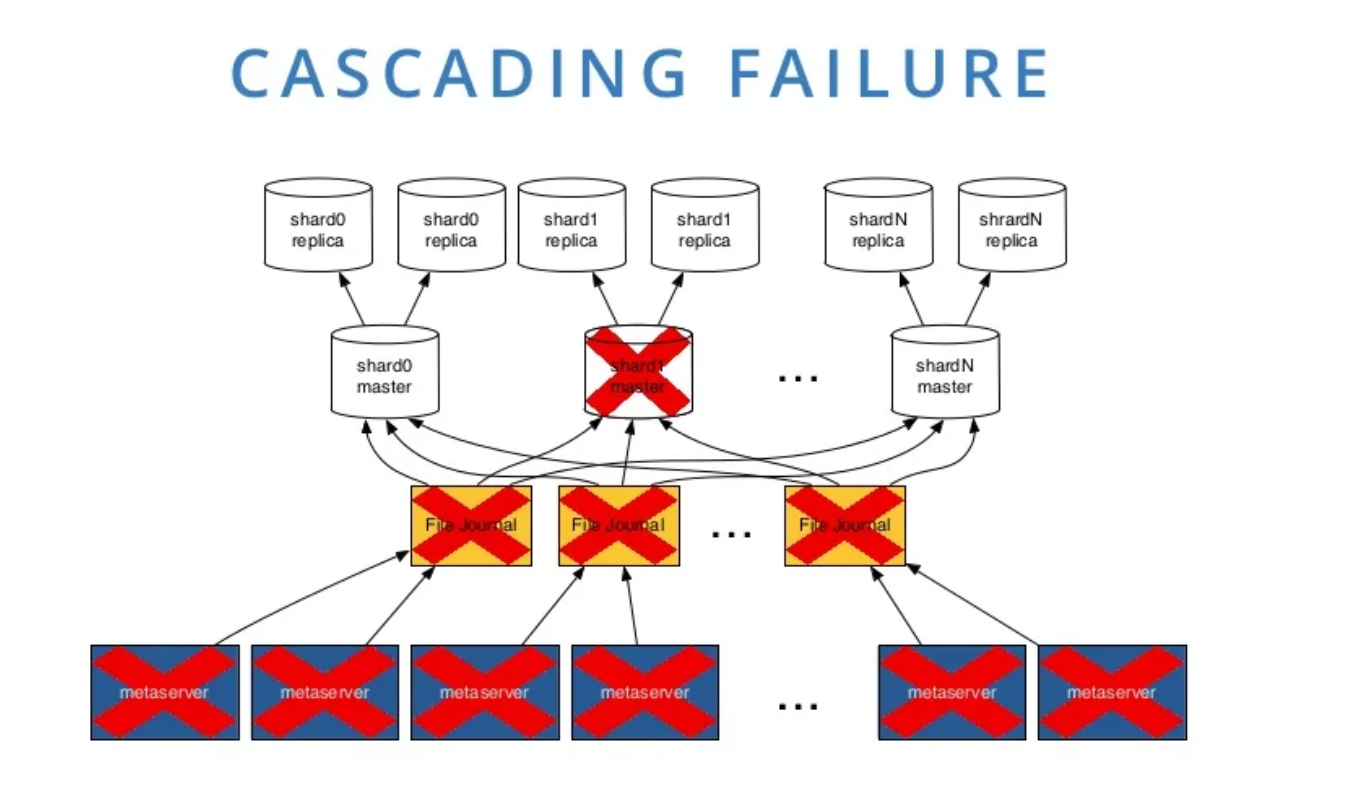
- Another example of cascading failures in sharding is when a shard goes down and exhausts the resources (workers, connections…) of the downstream services, that keep on waiting for it. The solution is to dedicate limited resources to each shard.
- Region Isolation is provided with Magic Pocket. Complexity is kept inside zones, which interface with each other through simple commands (get, put, delete…)
- To prevent cascading failures, Bandaid proxy provides per-route isolation using request queues.